 扫一扫
扫一扫大数据常用架构Lambda,iota分析
来源:未知 时间:2019-58-24 浏览次数:376次
1、流式架构传统大数据架构
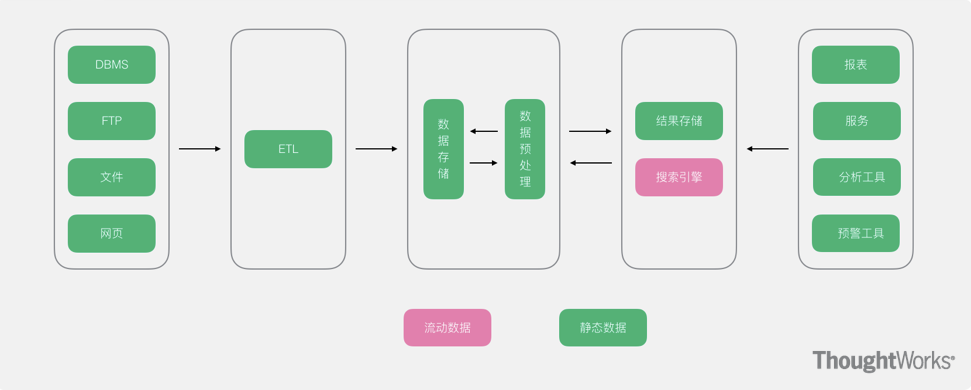
优点:简单,易懂,对于BI系统来说,基本思想没有发生变化,变化的仅仅是技术选型,用大数据架构替换掉BI的组件。
缺点:对于大数据来说,没有BI下如此完备的Cube架构,虽然目前有kylin,但是kylin的局限性非常明显,远远没有BI下的Cube的灵活度和稳定度,因此对业务支撑的灵活度不够,所以对于存在大量报表,或者复杂的钻取的场景,需要太多的手工定制化,同时该架构依旧以批处理为主,缺乏实时的支撑。
适用场景:数据分析需求依旧以BI场景为主,但是因为数据量、性能等问题无法满足日常使用。
2、流式架构
优点:没有臃肿的ETL过程,数据的实效性非常高。
缺点:对于流式架构来说,不存在批处理,因此对于数据的重播和历史统计无法很好的支撑。对于离线分析仅仅支撑窗口之内的分析。
适用场景:预警,监控,对数据有有效期要求的情况。
3、Lambda架构
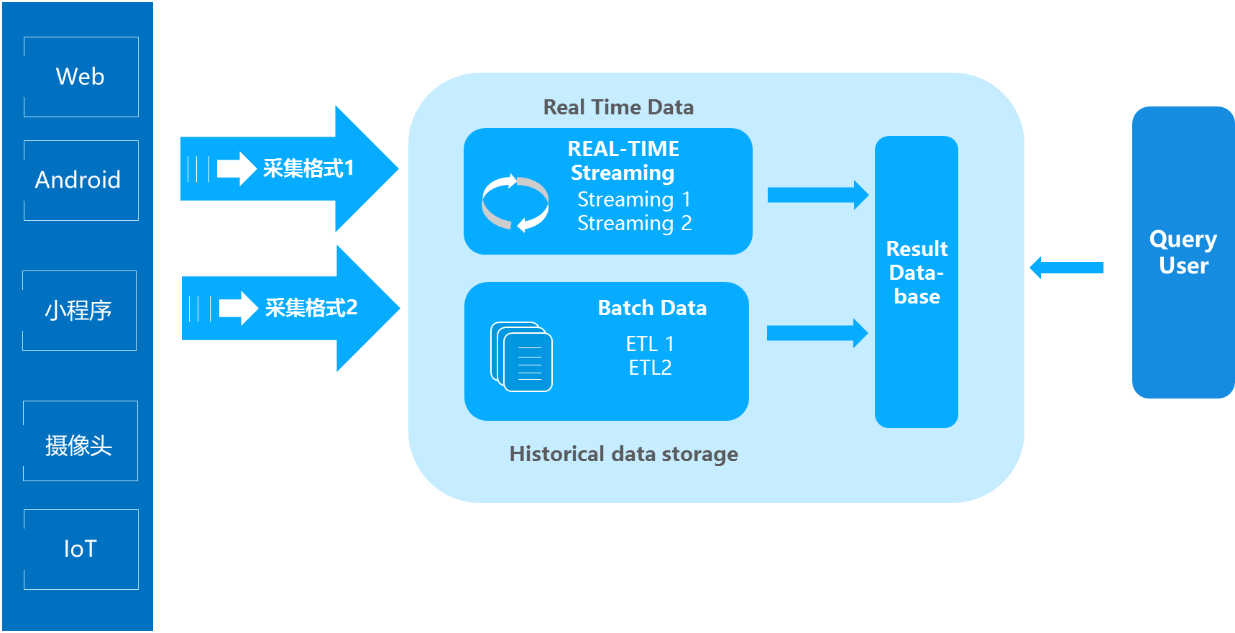
优点:既有实时又有离线,对于数据分析场景涵盖的非常到位。
缺点:离线层和实时流虽然面临的场景不相同,但是其内部处理的逻辑却是相同,因此有大量冗余和重复的模块存在。
适用场景:同时存在实时和离线需求的情况。
4、Kappa架构
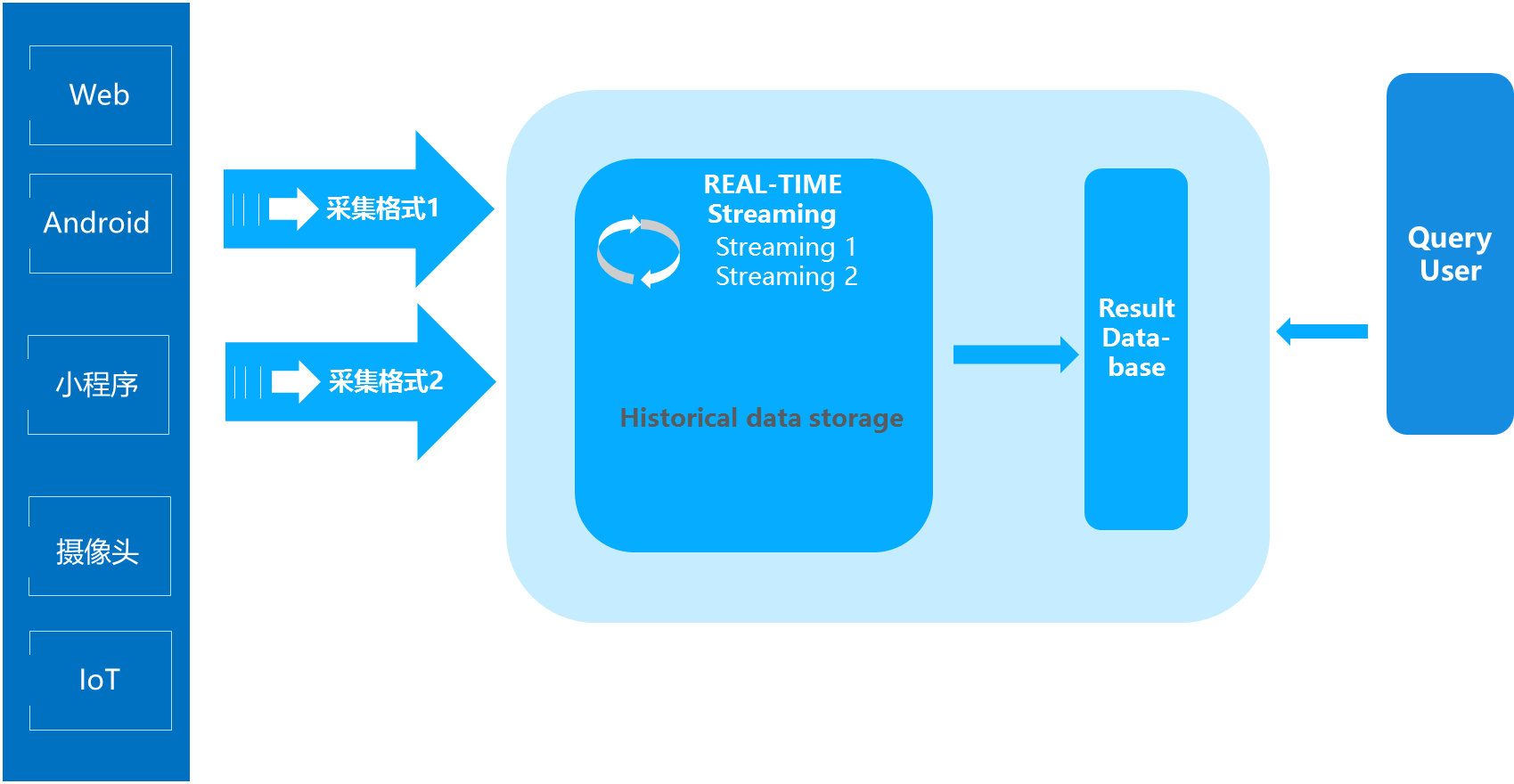
优点:Kappa架构的优点在于将实时和离线代码统一起来,方便维护而且统一了数据口径的问题
Kappa架构解决了Lambda架构里面的冗余部分,以数据可重播的超凡脱俗的思想进行了设计,整个架构非常简洁。
缺点:虽然Kappa架构看起来简洁,但是施难度相对较高,尤其是对于数据重播部分。
适用场景:和Lambda类似,改架构是针对Lambda的优化。
5、IOTA架构
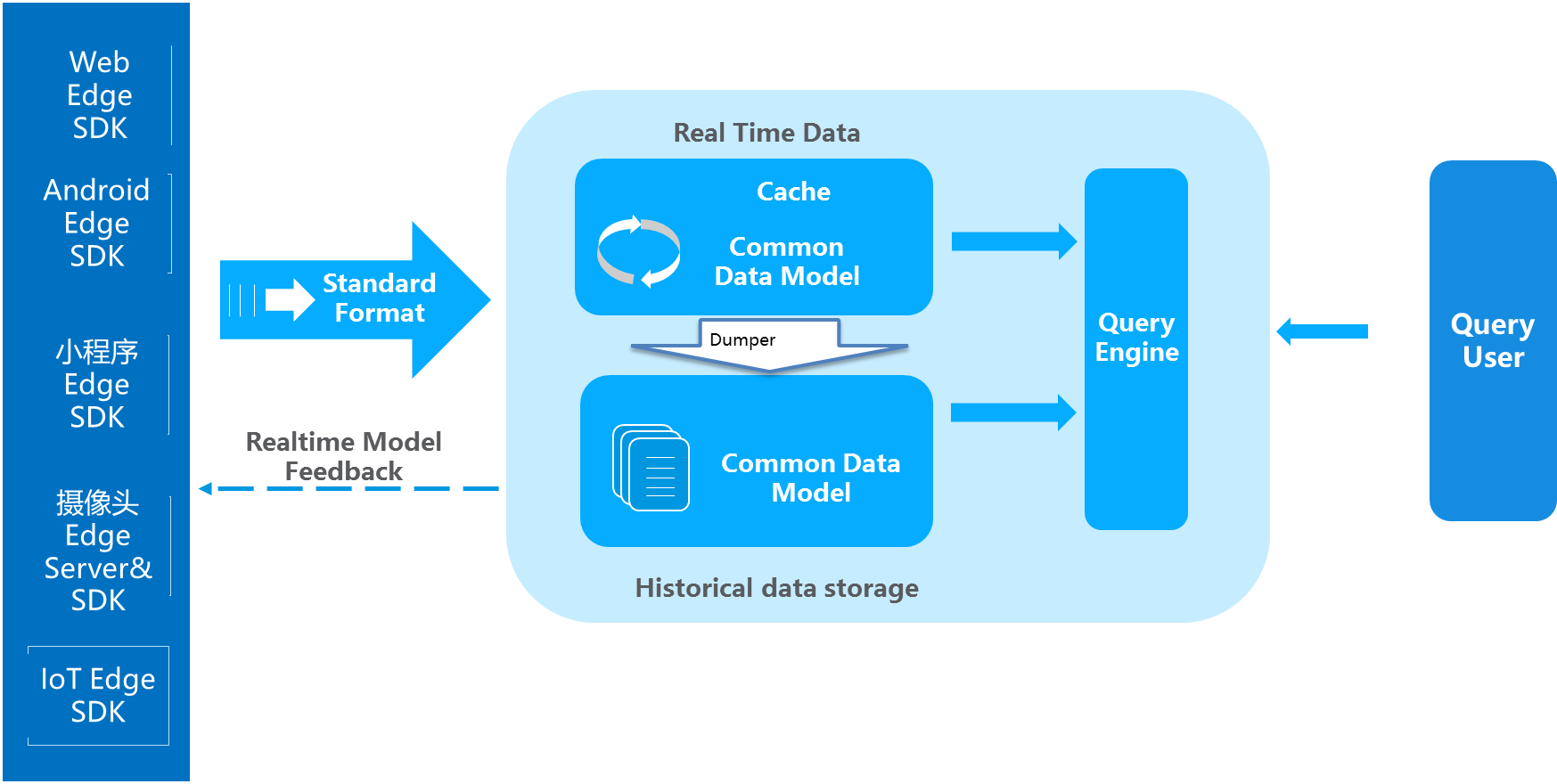
优点:
去ETL化:ETL和相关开发一直是大数据处理的痛点。TA架构通过Common Data Model的设计,专注在某一个具体领域的数据计算,从而可以从SDK端开始计算,中央端只做采集、建立索引和查询,提高整体数据分析的效率
Ad-hoc即时查询:鉴于整体的计算流程机制,在手机端、智能IOT事件发生之时,就可以直接传送到云端进入real time data区,可以被前端的Query Engine来查询。此时用户可以使用各种各样的查询,直接查到前几秒发生的事件,而不用在等待ETL或者Streaming的数据研发和处理。
边缘计算(Edge-Computing):将过去统一到中央进行整体计算,分散到数据产生、存储和查询端,数据产生既符合Common Data Model。同时,也给与Realtime model feedback,让客户端传送数据的同时马上进行反馈,而不需要所有事件都要到中央端处理之后再进行下发。
- 上一篇: 围绕hadoop开源流的大数据实现框架
- 下一篇: 企业级数据业务中台详解及使用技术