 扫一扫
扫一扫Hadoop之完全分布式环境搭建
来源:未知 时间:2021-38-16 浏览次数:227次
Hadoop之完全分布式环境搭建,搭建hbase,MapReduce,zookeeper大数据集群
硬件环境:CentOS 6.5 服务器4台(一台为Master节点,三台为Slave节点)
硬件环境:CentOS 6.5 服务器4台(一台为Master节点,三台为Slave节点)
软件环境:Java 1.7.0_45、hadoop-1.2.1
1、 集群拓扑图
我们使用4台机器来搭建Hadoop完全分布式环境,4台机器的拓扑图如下图所示:
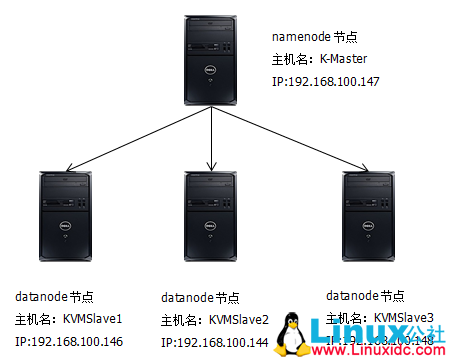
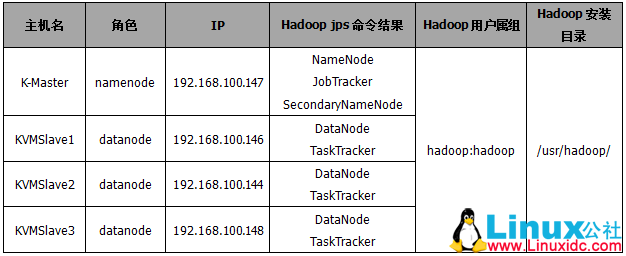
Hadoop集群中每个节点的角色如下表所示:
2、 配置SSH
- 环境准备
下面以配置K-Master启动SSH服务为例进行演示,用户需参照下面步骤完成KVMSlave1~KVMSlave3三台子节点机器的SSH服务启动;
1)以hadoop用户远程登录K-Master服务器,启动SSH服务;
[hadoop@K-Master hadoop]$ sudo /etc/init.d/sshd start
2)设置开机启动:
[hadoop@K-Master hadoop]$ sudo chkconfig sshd on
- 配置K-Master本机无密码登录
下面以配置K-Master本机无密码登录为例进行讲解,用户需参照下面步骤完成KVMSlave1~KVMSlave3三台子节点机器的本机无密码登录;
1)以hadoop用户远程登录K-Master服务器,在K-Master服务器上生成公钥和私钥密码对,密钥默认存储在”/home/hadoop/.ssh”目录下,生成公钥和私钥密码对时,无需输入密码,直接回车即可。
#切换到hadoop用户,不能使用root用户生成密钥 [hadoop@K-Master hadoop]$ su hadoop [hadoop@K-Master hadoop]$ cd /home/hadoop/ [hadoop@K-Master hadoop]$ ssh-keygen -t rsa -P ""
2)将公钥追加到”authorized_keys”文件
[hadoop@K-Master hadoop]$ cd /home/hadoop/ [hadoop@K-Master hadoop]$ cat .ssh/id_rsa.pub >> .ssh/authorized_keys
3)赋予权限
[hadoop@K-Master hadoop]$ chmod 600 .ssh/authorized_keys
4)验证本机能无密码访问
[hadoop@K-Master hadoop]$ ssh K-Master
- 配置K-Master本机无密码登录KVMSlave1~KVMSlave3
下面以K-Master无密码登录KVMSlave1为例进行讲解,用户需参照下面步骤完成K-Master无密码登录KVMSlave2~KVMSlave3。
1)以hadoop用户远程登录KVMSlave1服务器,复制K-Master服务器的公钥”id_rsa.pub”到KVMSlave1服务器的”/home/hadoop/”目录下。
[hadoop@KVMSlave1 hadoop]$ cd /home/hadoop/ [hadoop@KVMSlave1 hadoop]$ scp hadoop@K-Master:/home/hadoop/.ssh/id_rsa.pub /home/hadoop/
2)将K-Master的公钥(/home/hadoop/id_rsa.pub)追加到KVMSlave1的authorized_keys中。
[hadoop@KVMSlave1 hadoop]$ cd /home/hadoop [hadoop@KVMSlave1 hadoop]$ cat id_rsa.pub >> .ssh/authorized_keys [hadoop@KVMSlave1 hadoop]$ rm -r /home/hadoop/id_rsa.pub
3)另外开启一个终端,远程登录K-Master服务器,在K-Master服务器测试通过SSH无密码登录KVMSlave1。
[hadoop@K-Master hadoop]$ ssh KVMSlave1
- 配置KVMSlave1~KVMSlave3本机无密码登录K-Master
下面以KVMSlave1无密码登录K-Master为例进行讲解,用户需参照下面步骤完成KVMSlave2~KVMSlave3无密码登录K-Master。
1)以hadoop用户远程登录K-Master,复制KVMSlave1服务器的公钥”id_rsa.pub”到KVMSlave1服务器的”/home/hadoop/”目录下。
[hadoop@K-Master hadoop]$ scp hadoop@KVMSlave1:/home/hadoop/.ssh/id_rsa.pub /home/hadoop
2)将KVMSlave1的公钥(/home/hadoop/id_rsa.pub)追加到K-Master的authorized_keys中。
[hadoop@K-Master hadoop]$ cd /home/hadoop [hadoop@K-Master hadoop]$ cat id_rsa.pub >> .ssh/authorized_keys [hadoop@K-Master hadoop]$ rm –r /home/hadoop/id_rsa.pub
3)以hadoop用户远程登录KVMSlave1服务器,在KVMSlave1服务器测试通过SSH无密码登录K-Master。
[hadoop@KVMSlave1 hadoop]$ ssh K-Master
3、 安装Hadoop
如果用户已经完成了Hadoop伪分布式环境搭建,建议删除/usr/hadoop/安装环境,从零开始配置Hadoop完全分布式环境。
1)以hadoop用户远程登录K-Master服务器,下载hadoop-1.2.1.tar.gz ,并将其拷贝到K-Master服务器的/home/hadoop/目录下。
2)解压Hadoop源文件
[hadoop@K-Master ~]$ su hadoop [hadoop@K-Master ~]$ cd /usr [hadoop@K-Master usr]$ sudo tar -zxvf /home/hadoop/hadoop-1.2.1.tar.gz //将文件减压在当前路径
3)重命名hadoop
[hadoop@K-Master usr]$ sudo mv hadoop-1.2.1/ hadoop/
4) 设置hadoop文件夹的用户属组和用户组
很关键到一步,便于hadoop用户对该文件夹的文件拥有读写权限,不然后续hadoop启动后,无法在该文件夹创建文件和写入日志信息。
[hadoop@K-Master usr]$ sudo chown -R hadoop:hadoop /usr/hadoop
5)删除安装包
[hadoop@K-Master ~]$ rm -rf /home/hadoop/hadoop-1.2.1.tar.gz #删除"hadoop-1.2.1.tar.gz"安装包
4、 配置K-Master的hadoop环境
1)配置环境变量
[hadoop@K-Master ~]$ sudo vi /etc/profile #HADOOP export HADOOP_HOME=/usr/hadoop export PATH=$PATH:$HADOOP_HOME/bin export HADOOP_HOME_WARN_SUPPRESS=1
使得hadoop命令在当前终端立即生效;
[hadoop@K-Master ~] $source /etc/profile
2)配置hadoop-env.sh
hadoop环境是基于JVM虚拟机环境的,故需在hadoop-env.sh配置文件中指定JDK环境。修改/usr/hadoop/conf/hadoop-env.sh文件,添加如下JDK配置信息。
[hadoop@K-Master ~] cd /usr/hadoop/ [hadoop@K-Master hadoop] vi conf/hadoop-env.sh export JAVA_HOME=/usr/java/jdk1.7.0_65
3)配置core-site.xml
修改Hadoop核心配置文件/usr/hadoop/conf/core-site.xml,通过fs.default.name指定 NameNode 的 IP 地址和端口号,通过hadoop.tmp.dir指定hadoop数据存储的临时文件夹。
[hadoop@K-Master hadoop] vi conf/core-site.xml <configuration> <property> <name>fs.default.name</name> <value>hdfs://K-Master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/usr/hadoop/tmp</value> </property> </configuration>
特别注意:如没有配置hadoop.tmp.dir参数,此时系统默认的临时目录为:/tmp/hadoo-hadoop。而这个目录在每次重启后都会被删除,必须重新执行format才行,否则会出错。
4)配置hdfs-site.xml
修改HDFS核心配置文件/usr/hadoop/conf/hdfs-site.xml,通过dfs.replication指定HDFS的备份因子为3,通过dfs.name.dir指定namenode节点的文件存储目录,通过dfs.data.dir指定datanode节点的文件存储目录。
[hadoop@K-Master hadoop] vi conf/hdfs-site.xml <configuration> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.name.dir</name> <value>/usr/hadoop/hdfs/name</value> </property> <property> <name>dfs.data.dir</name> <value>/usr/hadoop/hdfs/data</value> </property> </configuration>
5)配置mapred-site.xml
修改MapReduce核心配置文件/usr/hadoop/conf/mapred-site.xml,通过mapred.job.tracker属性指定JobTracker的地址和端口。
[hadoop@K-Master hadoop] vi conf/mapred-site.xml <configuration> <property> <name>mapred.job.tracker</name> <value>http://K-Master:9001</value> </property> </configuration>
6)配置masters文件
修改/user/hadoop/conf/masters文件,该文件指定namenode节点所在的服务器机器。删除localhost,添加namenode节点的主机名K-Master;不建议使用IP地址,因为IP地址可能会变化,但是主机名一般不会变化。
[hadoop@K-Master hadoop] vi conf/masters K-Master
7)配置slaves文件(Master主机特有)
修改/usr/hadoop/conf/slaves文件,该文件指定哪些服务器节点是datanode节点。删除locahost,添加所有datanode节点的主机名,如下所示。
[hadoop@K-Master hadoop] vi conf/slaves KVMSlave1 KVMSlave2 KVMSlave3
5、 配置KVMSlave的hadoop环境
下面以配置KVMSlave1的hadoop为例进行演示,用户需参照以下步骤完成其他KVMSlave服务器的配置。
1)以hadoop用户远程登录KVMSlave1服务器,拷贝K-Master主机的hadoop文件夹到本地/usr/目录下;
[hadoop@KVMSlave1 ~]$ cd /usr/ [hadoop@KVMSlave1 usr]$ sudo scp -r hadoop@K-Master:/usr/hadoop/ . [hadoop@KVMSlave1 usr]$ sudo chown -R hadoop:hadoop hadoop/ #slaves文件内容删除,或者直接删除slaves [hadoop@KVMSlave1 usr]$ rm /usr/hadoop/conf/slaves
2)配置环境变量
[hadoop@KVMSlave1 ~]$ sudo vi /etc/profile #HADOOP export HADOOP_HOME=/usr/hadoop export PATH=$PATH:$HADOOP_HOME/bin export HADOOP_HOME_WARN_SUPPRESS=1
使得hadoop命令在当前终端立即生效;
[hadoop@KVMSlave1 ~]$ source /etc/profile
6、 格式化HDFS文件系统
格式化HDFS文件系统需要在namenode节点上通过hadoop用户执行,而且只需要执行一次,下次启动时不需要��格式化,直接启动HDFS文件管理系统和MapReduce服务即可。
[hadoop@K-Master ~]$ hadoop namenode -format 14/07/24 16:37:57 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = K-Master/192.168.100.147 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 1.2.1 STARTUP_MSG: build = https://svn.apache.org/repos/asf/hadoop/common/branches/branch-1.2 -r 1503152; compiled by 'mattf' on Mon Jul 22 15:23:09 PDT 2013 STARTUP_MSG: java = 1.7.0_65 ********************a****************************************/ 14/07/24 16:37:57 INFO util.GSet: Computing capacity for map BlocksMap 14/07/24 16:37:57 INFO util.GSet: VM type = 64-bit 14/07/24 16:37:57 INFO util.GSet: 2.0% max memory = 932184064 14/07/24 16:37:57 INFO util.GSet: capacity = 2^21 = 2097152 entries 14/07/24 16:37:57 INFO util.GSet: recommended=2097152, actual=2097152 14/07/24 16:37:58 INFO namenode.FSNamesystem: fsOwner=hadoop 14/07/24 16:37:58 INFO namenode.FSNamesystem: supergroup=supergroup 14/07/24 16:37:58 INFO namenode.FSNamesystem: isPermissionEnabled=true 14/07/24 16:37:58 INFO namenode.FSNamesystem: dfs.block.invalidate.limit=100 14/07/24 16:37:58 INFO namenode.FSNamesystem: isAccessTokenEnabled=false accessKeyUpdateInterval=0 min(s), accessTokenLifetime=0 min(s) 14/07/24 16:37:58 INFO namenode.FSEditLog: dfs.namenode.edits.toleration.length = 0 14/07/24 16:37:58 INFO namenode.NameNode: Caching file names occuring more than 10 times 14/07/24 16:37:58 INFO common.Storage: Image file /usr/hadoop/hdfs/name/current/fsimage of size 112 bytes saved in 0 seconds. 14/07/24 16:37:59 INFO namenode.FSEditLog: closing edit log: position=4, editlog=/usr/hadoop/hdfs/name/current/edits 14/07/24 16:37:59 INFO namenode.FSEditLog: close success: truncate to 4, editlog=/usr/hadoop/hdfs/name/current/edits 14/07/24 16:37:59 INFO common.Storage: Storage directory /usr/hadoop/hdfs/name has been successfully formatted. 14/07/24 16:37:59 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at K-Master/192.168.100.147 ************************************************************/
7、 启动HDFS文件管理系统
1)通过start-dfs.sh命令启动HDFS文件管理系统,启动后通过如下日志信息可以看到分别启动了namenode节点(K-Master)、datanode节点(KVMSlave1、KVMSlave2、KVMSlave3)和secondarynamenode节点(K-Master)。
[hadoop@K-Master ~]$ start-dfs.sh starting namenode, logging to /usr/hadoop/libexec/../logs/hadoop-hadoop-namenode-K-Master.out KVMSlave1: starting datanode, logging to /usr/hadoop/libexec/../logs/hadoop-hadoop-datanode-KVMSlave1.out KVMSlave2: starting datanode, logging to /usr/hadoop/libexec/../logs/hadoop-hadoop-datanode-KVMSlave2.out KVMSlave3: starting datanode, logging to /usr/hadoop/libexec/../logs/hadoop-hadoop-datanode-KVMSlave3.out K-Master: starting secondarynamenode, logging to /usr/hadoop/libexec/../logs/hadoop-hadoop-secondarynamenode-K-Master.out
2)在K-Master节点上查看启动进程
若打印如下日志信息,表明namenode节点启动了NameNode和SecondaryNameNode2服务进程,即namenode节点HDFS文件管理系统启动成功。
[hadoop@K-Master ~]$ jps 6164 Jps 5971 NameNode 6108 SecondaryNameNode
3)在KVMSlave1节点上查看启动进程
以hadoop用户远程登录KVMSlave1服务器,通过jps命令查看启动进程。若打印如下日志信息,表明datanode节点启动了DataNode服务进程,即KVMSlave1节点HDFS文件管理系统启动成功,用户可在远程登录其他datanode节点上查看其HDFS文件管理系统启动是否成功。
[hadoop@KVMSlave1 ~]$ jps 1327 Jps 1265 DataNode
8、 启动MapReduce
1)通过start-mapred.sh命令启动MapReduce分布式计算服务,启动后通过以下日志信息可以看出在namenode节点上启动了jobtracker进程,分别在datanode节点(KVMSlave1、KVMSlave2、KVMSlave3)上启动了tasktracker进程。
[hadoop@K-Master ~]$ start-mapred.sh starting jobtracker, logging to /usr/hadoop/libexec/../logs/hadoop-hadoop-jobtracker-K-Master.out KVMSlave1: starting tasktracker, logging to /usr/hadoop/libexec/../logs/hadoop-hadoop-tasktracker-KVMSlave1.out KVMSlave2: starting tasktracker, logging to /usr/hadoop/libexec/../logs/hadoop-hadoop-tasktracker-KVMSlave2.out KVMSlave3: starting tasktracker, logging to /usr/hadoop/libexec/../logs/hadoop-hadoop-tasktracker-KVMSlave3.out
2)K-Master节点上查看启动进程
若打印如下日志信息,表明namenode节点上新启动了JobTracker进程,即namenode节点的JobTracker启动成功。
[hadoop@K-Master ~]$ jps 1342 NameNode 1726 Jps 1619 JobTracker 1480 SecondaryNameNode
3)KVMSlave1节点上查看启动进程
以hadoop用户远程登录KVMSlave1服务器,通过jps命令查看启动进程。若打印如下日志信息,表明KVMSlave1节点上新启动了TaskTracker进程,即KVMSlave1节点的TaskTracker启动成功。用户可远程登录其他的datanode节点上查看TaskTracker是否启动成功。
[hadoop@KVMSlave1 ~]$ jps 1549 TaskTracker 1265 DataNode 1618 Jps
9、 命令查看Hadoop集群的状态
通过简单的jps命令虽然可以查看HDFS文件管理系统、MapReduce服务是否启动成功,但是无法查看到Hadoop整个集群的运行状态。我们可以通过hadoop dfsadmin -report进行查看。用该命令可以快速定位出哪些节点挂掉了,HDFS的容量以及使用了多少,以及每个节点的硬盘使用情况。
[hadoop@K-Master ~]$ hadoop dfsadmin -report Configured Capacity: 238417846272 (222.04 GB) Present Capacity: 219128426496 (204.08 GB) DFS Remaining: 218227326976 (203.24 GB) DFS Used: 901099520 (859.36 MB) DFS Used%: 0.41% Under replicated blocks: 72 Blocks with corrupt replicas: 0 Missing blocks: 0 ------------------------------------------------- Datanodes available: 3 (3 total, 0 dead) Name: 192.168.100.144:50010 Decommission Status : Normal Configured Capacity: 79472615424 (74.01 GB) DFS Used: 300367872 (286.45 MB) Non DFS Used: 6218309632 (5.79 GB) DFS Remaining: 72953937920(67.94 GB) DFS Used%: 0.38% DFS Remaining%: 91.8% Last contact: Tue Feb 03 16:50:00 CST 2015 Name: 192.168.100.148:50010 Decommission Status : Normal Configured Capacity: 79472615424 (74.01 GB) DFS Used: 300367872 (286.45 MB) Non DFS Used: 6242603008 (5.81 GB) DFS Remaining: 72929644544(67.92 GB) DFS Used%: 0.38% DFS Remaining%: 91.77% Last contact: Tue Feb 03 16:49:59 CST 2015 Name: 192.168.100.146:50010 Decommission Status : Normal Configured Capacity: 79472615424 (74.01 GB) DFS Used: 300363776 (286.45 MB) Non DFS Used: 6828507136 (6.36 GB) DFS Remaining: 72343744512(67.38 GB) DFS Used%: 0.38% DFS Remaining%: 91.03% Last contact: Tue Feb 03 16:50:00 CST 2015