 扫一扫
扫一扫XHESDB大数据智能化管理平台技术方案
来源:未知 时间:2021-53-27 浏览次数:157次
一.大数据云计算平台
- 平台体系架构
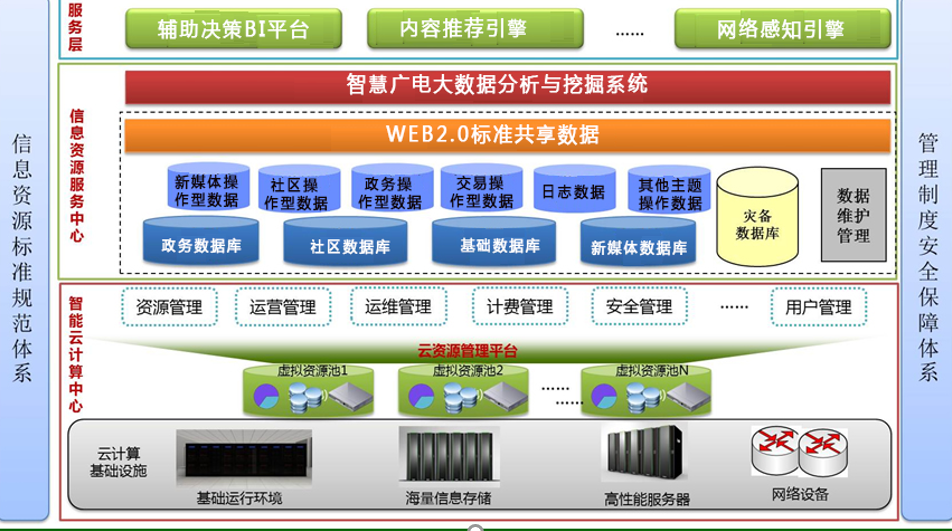
2.云计算平台业务示意
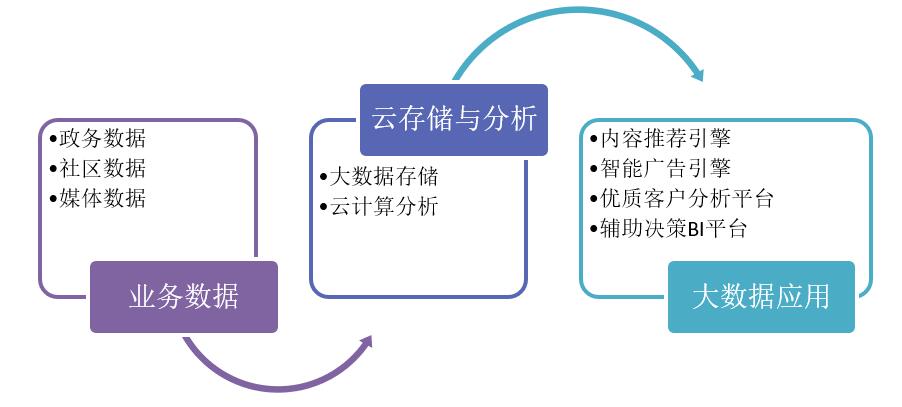
3.云计算平台技术核心示意
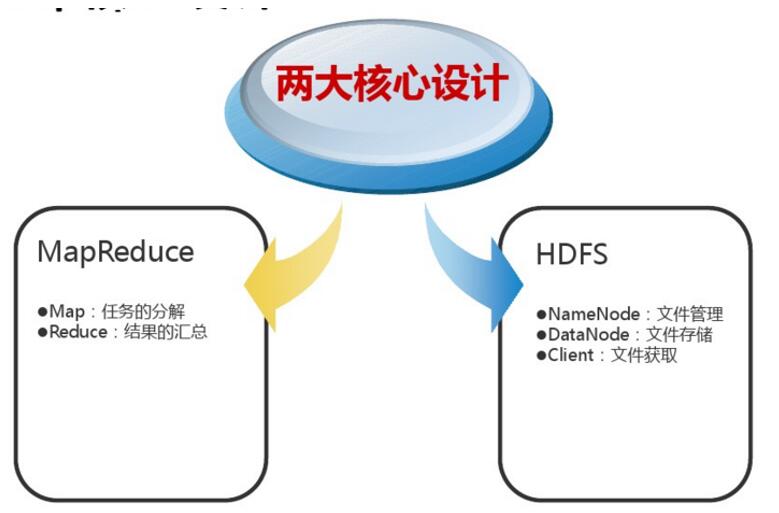
二.大数据存储系统
1.大数据挖掘
使用大数据挖掘技术神经网络,决策树方法,粗集方法对各个业务平台基础业务数据进行挖掘,使用海量数据存储技术对用户操作数据建立主题挖掘与存储
2.大数据存储
使用HDFS搭建高可用存储架构,存储视频,文件等块性数据,使用HBASE数据库集群存储业务和主题操作型数据,以备只能分析系统做云决策分析
1.用户操作数据存储系统
收集社区平台,政务平台,新媒体平台用户操作数据并做数据兼容性集成存储到云存储系统
2.用户推荐
经过云算法将商品,文章,广告信息推荐到用户端,包括PC网站,手机APP,微信端等
3.客户数据存储与分析
收集社区平台,政务平台,O2O电商平台用户操作与交易数据并做数据兼容性集成存储到云存储系统,通过优质客户分析算法映射出优质用户数据
4.运营平台商机管理
展示通过分析得到的优质客户资源,对优质客户资源进行多维度动态查看,包括客户分类(广告客户,商家客户等,产品使用用户),按客户优质度等查看客户明细,对客户跟踪商务情况
3.商家系统商机管理
展示通过分析行业客户数据得到的对应优质客户资源,对优质客户资源进行多维度动态查看,生成多维度动态统计分析报表(HADOOP-DTL)展示分析结果,供商家决策使用
三.辅助决策BI平台
三.辅助决策BI平台
1.数据集成
数据是决策分析的基础。很多情况下,决策需要的数据零散分布在几个业务系统中,为了做出正确的经营决策,就需要把这些零散的数据收集起来,形成一个系统的整体。因此从多个异构数据源,包括内部的业务系统和外部的数据源提取源数据,再经过一定的变换后装载到数据仓库,实现数据的集成是必要的。
2.信息呈现
信息呈现把收集的数据以报表的形式呈现出来,让用户了解到企业、市场现状。这是商务智能的初步功能。例如BusinessObjects(SAP)的水晶报表(crystalreports)允许从各种数据源收集数据,使报表分析人员可以随心所欲、快速便捷地设计报表。在信息呈现的方式上,除了报表、图等形式以外,还可以用其他直观的方式。此外,利用在线分析处理(OLAP),也可以从多个维度观察数据。
3.运营分析
运营分析包括运营指标分析、运营业绩分析和财务分析等。运营指标分析是指对企业不同的业务流程和业务环节的指标进行分析,运营业绩分析是指对各部门的营业额、销售量等进行统计,在此基础上进行同期比较分析、应收分析、盈亏分析和各种商品的风险分析等。财务分析是指对利润、费用支出、资金占用以及其他经济指标进行分析,及时掌握企业在资金使用方面的实际情况,调整和降低企业成本。运营分析包括多方面的内容
4.战略决策支持
战略决策支持是指根据公司各战略业务单元(SBU)的经营业绩和定位,选择一种合理的投资组合战略。由于商务智能系统集成了外部数据,例如外部环境和行业信息,各战略业务单元可据此制定自身的竞争战略。此外,企业还可以利用业务运营的数据,提供营销、生产、财务和人力资源等决策支持
四.大数据与云计算管理平台
四.大数据与云计算管理平台
- 硬件管理与集成
根据实际数据存储数据数量增加通过管理平台动态增加实体硬件(服务器,网络)的接入和集成,使云平台自动完成新接入硬件的自动化部署与初始化
硬件监控,通过实时报表和动态统计图显示各硬件与基础设施运行状况,对于运行故障分等级自动通知管理员(邮件,短信)
硬件监控,通过实时报表和动态统计图显示各硬件与基础设施运行状况,对于运行故障分等级自动通知管理员(邮件,短信)
- 分布式存储管理Hadoop Distributed File System
HDFS权限管理,通过管理平台设置HDFS name-node与存储块儿区的用户访问权限
通过管理平台设置HDFS存储空间,格式化存储空间
通过管理平台设置HDFS存储空间,格式化存储空间
- 分布式计算管理
分布式计算服务器分配 ,通过管理平台分配云计算服务器资源
云计算计划任务,通过管理平台界面设置云计算分析任务,任务设定后根据是设定时间按计划执行云计算与分析等任务
云计算算法设计器,开发专属云计算算法设计器,通过业务逻辑描述和信息分析描述生成云计算算法,自动运行产生数据映射mapping
云计算计划任务,通过管理平台界面设置云计算分析任务,任务设定后根据是设定时间按计划执行云计算与分析等任务
云计算算法设计器,开发专属云计算算法设计器,通过业务逻辑描述和信息分析描述生成云计算算法,自动运行产生数据映射mapping
- Hive用户接口
已经WEB2.0标准,对外提供标准大数据开发接口对业务内部童工SQL操作接口
五.总体架构
2.1设计原则
整个系统框架设计遵循如下原则:
(1)易维护性;
本系统架构采用灵活架构,代码复用的可维护性设计方法,尽量减少各模块相互之间的依赖项,采用成熟的工业应用级的产品和框架,采用代码审查机制等手段来进行系统框架易维护性的开发设计。传统软件工程用可理解性、可测试性和可修改性来衡量软件的可维护性,CASE软件工程则以考察可重用性来衡量可维护性。可维护性最直接的体现是良好的软件结构和完整正确的文档体系。维护应在文档级以上展开,应从软件结构出发,即以重构为核心。可重用性是可维护性的基本属性,最大限度地重用现存软件是软件维护方法学的重要思想原则。
系统架构的维护包括两方面,一是排除现有的错误,二是将新的软件需求反映到现有系统中去。一个易于维护的系统可以有效地降低技术支持的花费。在系统设计的每个阶段都要努力提高系统的可维护性,在每个阶段结束前的审查和复审中,着重对可维护性进行复审。
(2)易扩展性;
由于大数据分布式处理(一期)项目的业务需求快速发展、业务不断变化,所以系统必须具有高扩展性,大数据分布式处理(一期)项目不是固定不变的业务平台,而是一个逐步发展的应用系统,所有系统结构、设备都在标准性、开放性原则的基础上做到可灵活扩展,以适应用户需求的不断增加和变化。当用户数目扩展、业务范围拓展时,系统能以灵活调整、扩充的手段、方法来适应其变化;并且考虑到与现有业务系统的对接,本系统均采用分布式、模块化设计的产品,从而能随时增加模块业务扩充功能和能力。按照技术发展的趋势,以较低的成本实现技术的更新换代,从而提高系统投资的综合性价比和长期稳定使用,保护已有的设备、技术投资。
(3)安全可靠性;
现在的计算机病毒几乎都来自于网络,系统尽量采用五层安全体系,即网络层安全、系统层安全、数据层安全、应用层安全、管理层安全。系统具备高可靠性,对使用信息进行严格的权限管理,技术上,应采用严格的安全与保密措施,保证系统的可靠性、保密性和数据一致性等。
(4)面向服务的体系结构等要求,以便于各个业务系统间的整合。
(5)基于插件模式设计
整个系统架构平台采用插件模式来构建和扩展业务系统, 将各类分散的机关单位已有应用系统整合起来,形成一个紧密联系的整体。
(1)易维护性;
本系统架构采用灵活架构,代码复用的可维护性设计方法,尽量减少各模块相互之间的依赖项,采用成熟的工业应用级的产品和框架,采用代码审查机制等手段来进行系统框架易维护性的开发设计。传统软件工程用可理解性、可测试性和可修改性来衡量软件的可维护性,CASE软件工程则以考察可重用性来衡量可维护性。可维护性最直接的体现是良好的软件结构和完整正确的文档体系。维护应在文档级以上展开,应从软件结构出发,即以重构为核心。可重用性是可维护性的基本属性,最大限度地重用现存软件是软件维护方法学的重要思想原则。
系统架构的维护包括两方面,一是排除现有的错误,二是将新的软件需求反映到现有系统中去。一个易于维护的系统可以有效地降低技术支持的花费。在系统设计的每个阶段都要努力提高系统的可维护性,在每个阶段结束前的审查和复审中,着重对可维护性进行复审。
(2)易扩展性;
由于大数据分布式处理(一期)项目的业务需求快速发展、业务不断变化,所以系统必须具有高扩展性,大数据分布式处理(一期)项目不是固定不变的业务平台,而是一个逐步发展的应用系统,所有系统结构、设备都在标准性、开放性原则的基础上做到可灵活扩展,以适应用户需求的不断增加和变化。当用户数目扩展、业务范围拓展时,系统能以灵活调整、扩充的手段、方法来适应其变化;并且考虑到与现有业务系统的对接,本系统均采用分布式、模块化设计的产品,从而能随时增加模块业务扩充功能和能力。按照技术发展的趋势,以较低的成本实现技术的更新换代,从而提高系统投资的综合性价比和长期稳定使用,保护已有的设备、技术投资。
(3)安全可靠性;
现在的计算机病毒几乎都来自于网络,系统尽量采用五层安全体系,即网络层安全、系统层安全、数据层安全、应用层安全、管理层安全。系统具备高可靠性,对使用信息进行严格的权限管理,技术上,应采用严格的安全与保密措施,保证系统的可靠性、保密性和数据一致性等。
(4)面向服务的体系结构等要求,以便于各个业务系统间的整合。
(5)基于插件模式设计
整个系统架构平台采用插件模式来构建和扩展业务系统, 将各类分散的机关单位已有应用系统整合起来,形成一个紧密联系的整体。
2.3平台逻辑功能架构
平台核心系统包括:离线计算,工作流调度和分析结果。另外还有支持系统,包括调度系统和管理系统,负责各项数据处理任务的调度,监测分析平台设备和数据分析任务的运行状况,
离线计算,主要是批量分析日志数据,生成需要的数据。对于一个数据处理任务,需定制开发Map Reduce的工作任务来进行。
工作流调度,在分析平台中,有大量的任务是定时驱动,如从业务平台拉取日志信息,同步业务数据库中数据,每个报表对应的数据分析任务等等,调度代理的主要作用就是根据数据分析的业务逻辑,驱动对应的任务按预期执行,并监控执行状态和结果。
调度系统,为数据分析实际生产平台的任务的管理入口,通过驱动代理来控制分析平台任务的启动、执行和停止,并监控任务的执行状态。同时,也控制着新增任务的导入和失效任务的删除。
管理系统,负责分析平台集群的部署,和各服务进程和硬件设备的状态,保证集群的硬件设备正常工作,服务进程正常执行调度系统的指派的任务。
离线计算,主要是批量分析日志数据,生成需要的数据。对于一个数据处理任务,需定制开发Map Reduce的工作任务来进行。
工作流调度,在分析平台中,有大量的任务是定时驱动,如从业务平台拉取日志信息,同步业务数据库中数据,每个报表对应的数据分析任务等等,调度代理的主要作用就是根据数据分析的业务逻辑,驱动对应的任务按预期执行,并监控执行状态和结果。
调度系统,为数据分析实际生产平台的任务的管理入口,通过驱动代理来控制分析平台任务的启动、执行和停止,并监控任务的执行状态。同时,也控制着新增任务的导入和失效任务的删除。
管理系统,负责分析平台集群的部署,和各服务进程和硬件设备的状态,保证集群的硬件设备正常工作,服务进程正常执行调度系统的指派的任务。
2.3总体技术架构
本次系统总体技术支撑平台将采用行业领先的技术架构和中间件技术,充分考虑到未来的扩展性、使用的灵活性、数据网络的安全性,以下为本次采用的技术架构及关键技术点。
大数据分布式处理平台包含了三个层次:计算与存储层、应用挖掘层,以及访问接口层。
注:实线框内的分布式计算平台是本次项目实施范围内需要建设的内容,虚线框内的实时流处理是未来可以扩展的。不在本期项目建设范围之内。
计算与存储层
计算与存储层主要是基于Hadoop平台体系构建而成,具有高模块化和松耦合的五层架构,针对不同的应用领域通过组件之间的灵活组合与高效协作来提供定制化的支撑。
存储层
数据存储层: 基于HDFS2.2的大数据存储和在线服务系,支持Erasure Code,在副本数降低至1.4倍的情况下,可同时容忍四个数据块丢失,支持可靠存储TB到数十PB的数据。
资源管理层:缺省采用下一代资源管理框架YARN进行资源的分配和调度,支持同时运行多个计算框架;
计算引擎层:采用Map/Reduce2完成大部分离线批处理计算任务。
数据分析与挖掘层:支持离线批量SQL统计,支持R语言以及机器学习算法库Mahout.
数据集成层:Sqoop支持从DB到Hadoop的数据迁移,Flume支持从日志系统采集数据。
计算层
计算层主要包含两大组件,内存计算分析引擎Inceptor和实时在线数据处理引擎Hyperbase。
1)Inceptor内存分析引擎提供大数据的交互式SQL统计和R语言挖掘能力。
高性能:Inceptor支持将二维数据表缓存入独立的分布式内存(或SSD)中,建立列式存储、分区/分块和索引,采用改进后的Apache Spark作为执行引擎,SQL执行性能比Apache Hadoop/Hive快10~100倍左右,性能超过主流MPP数据库2倍到10倍。Inceptor处理的数据不局限在内存中,即使数据在低速磁盘上,SQL执行性能也比Apache Hadoop/Hive快5到20倍。
更强的SQL支持:Inceptor同时兼容Oracle PL/SQL和HiveQL语法,自动识别不同语法,支持存储过程和函数,支持常用Oracle扩展函数。完整的SQL支持帮助了用户平滑地从原有关系数据库迁移到大数据平台。
更强的统计分析能力:用户可以通过RStudio或者R命令行访问存储在分布式内存中的数据,R语言中数千个统计算法可以和Inceptor提供的分布式并行数据挖掘算法交替混合使用,为各行业进行大数据挖掘提供了易用而强大的分析工具;
支持广泛的BI和报表工具:Inceptor可以和常用的BI工具对接,包括Tableau, SAP Business Objects, Oracle OBIEE等,用户无需编程就可以方便地为大数据创建美丽的报表,通过Inceptor提供的高速大数据统计分析能力提高决策效率;高扩展能力:Inceptor可以随着集群规模的扩展,线性扩展处理能力,可以支持从GB到数百TB的数据处理。
2)Hyperbase实时在线数据处理引擎以Apache HBase为基础,是企业建立高并发的在线业务系统的最佳选择。
多种数据类型支持:Hyperbase支持从GB到数十PB数据的处理,支持广泛的数据类型,包括对结构化记录、半结构化文本、图数据、非结构化数据(图片、音频、二进制文档等)的存储、搜索、统计和分析。
高速数据处理能力:Hyperbase支持高速的数据检索、搜索和统计;根据索引进行检索的延时在数毫秒到数百毫秒量级;支持上亿的并发用户同时进行数据插入、修改、查询和检索;支持对文本建立增量全文索引并且支持秒级的全文关键字搜索。
高效OLAP和批量统计:Hyperbase为Inceptor引擎提供高效数据扫描接口,通过Inceptor的扩展SQL语法,充分利用Hyperbase的内部数据结构以及全局/辅助索引进行SQL执行加速,可以满足高速的OLAP数据分析应用需求;同时也支持高速的SQL离线批处理,性能接近于存储在HDFS上的相同数据的统计。
高效图计算:Hyperbase提供构造图形的API,帮助用户构造由上亿顶点组成的复杂大图,同时提供专有的高效图算法,包括关联网络的高速分析。
应用挖掘层
主要是指基于分布式处理支撑平台上的应用挖掘业务展现。
访问接口层
主要是指分布式处理平台所提供的各种接口服务,以便第三方业务应用调用和集成,为公安的上层业务应用提供分布式计算和存储的支撑
全部文档下载地址:
大数据分布式处理平台包含了三个层次:计算与存储层、应用挖掘层,以及访问接口层。
注:实线框内的分布式计算平台是本次项目实施范围内需要建设的内容,虚线框内的实时流处理是未来可以扩展的。不在本期项目建设范围之内。
计算与存储层
计算与存储层主要是基于Hadoop平台体系构建而成,具有高模块化和松耦合的五层架构,针对不同的应用领域通过组件之间的灵活组合与高效协作来提供定制化的支撑。
存储层
数据存储层: 基于HDFS2.2的大数据存储和在线服务系,支持Erasure Code,在副本数降低至1.4倍的情况下,可同时容忍四个数据块丢失,支持可靠存储TB到数十PB的数据。
资源管理层:缺省采用下一代资源管理框架YARN进行资源的分配和调度,支持同时运行多个计算框架;
计算引擎层:采用Map/Reduce2完成大部分离线批处理计算任务。
数据分析与挖掘层:支持离线批量SQL统计,支持R语言以及机器学习算法库Mahout.
数据集成层:Sqoop支持从DB到Hadoop的数据迁移,Flume支持从日志系统采集数据。
计算层
计算层主要包含两大组件,内存计算分析引擎Inceptor和实时在线数据处理引擎Hyperbase。
1)Inceptor内存分析引擎提供大数据的交互式SQL统计和R语言挖掘能力。
高性能:Inceptor支持将二维数据表缓存入独立的分布式内存(或SSD)中,建立列式存储、分区/分块和索引,采用改进后的Apache Spark作为执行引擎,SQL执行性能比Apache Hadoop/Hive快10~100倍左右,性能超过主流MPP数据库2倍到10倍。Inceptor处理的数据不局限在内存中,即使数据在低速磁盘上,SQL执行性能也比Apache Hadoop/Hive快5到20倍。
更强的SQL支持:Inceptor同时兼容Oracle PL/SQL和HiveQL语法,自动识别不同语法,支持存储过程和函数,支持常用Oracle扩展函数。完整的SQL支持帮助了用户平滑地从原有关系数据库迁移到大数据平台。
更强的统计分析能力:用户可以通过RStudio或者R命令行访问存储在分布式内存中的数据,R语言中数千个统计算法可以和Inceptor提供的分布式并行数据挖掘算法交替混合使用,为各行业进行大数据挖掘提供了易用而强大的分析工具;
支持广泛的BI和报表工具:Inceptor可以和常用的BI工具对接,包括Tableau, SAP Business Objects, Oracle OBIEE等,用户无需编程就可以方便地为大数据创建美丽的报表,通过Inceptor提供的高速大数据统计分析能力提高决策效率;高扩展能力:Inceptor可以随着集群规模的扩展,线性扩展处理能力,可以支持从GB到数百TB的数据处理。
2)Hyperbase实时在线数据处理引擎以Apache HBase为基础,是企业建立高并发的在线业务系统的最佳选择。
多种数据类型支持:Hyperbase支持从GB到数十PB数据的处理,支持广泛的数据类型,包括对结构化记录、半结构化文本、图数据、非结构化数据(图片、音频、二进制文档等)的存储、搜索、统计和分析。
高速数据处理能力:Hyperbase支持高速的数据检索、搜索和统计;根据索引进行检索的延时在数毫秒到数百毫秒量级;支持上亿的并发用户同时进行数据插入、修改、查询和检索;支持对文本建立增量全文索引并且支持秒级的全文关键字搜索。
高效OLAP和批量统计:Hyperbase为Inceptor引擎提供高效数据扫描接口,通过Inceptor的扩展SQL语法,充分利用Hyperbase的内部数据结构以及全局/辅助索引进行SQL执行加速,可以满足高速的OLAP数据分析应用需求;同时也支持高速的SQL离线批处理,性能接近于存储在HDFS上的相同数据的统计。
高效图计算:Hyperbase提供构造图形的API,帮助用户构造由上亿顶点组成的复杂大图,同时提供专有的高效图算法,包括关联网络的高速分析。
应用挖掘层
主要是指基于分布式处理支撑平台上的应用挖掘业务展现。
访问接口层
主要是指分布式处理平台所提供的各种接口服务,以便第三方业务应用调用和集成,为公安的上层业务应用提供分布式计算和存储的支撑
全部文档下载地址:
 |
XHESDB大数据智能化管理平台技术方案 |
- 上一篇: 区县级智慧党建平台功能需求
- 下一篇: 工会困难职工帮扶平台设计方案