 扫一扫
扫一扫PDF及图片资源内容识别与智能归档系统解决方案
来源:未知 时间:2018-21-7 浏览次数:224次
1.1.1 资源加工处理
资源元数据 :即PDF 文件的 基本信息:标题 作者、关键词、摘要、时间等数据项。1.1.1.1 资源加工大体功能
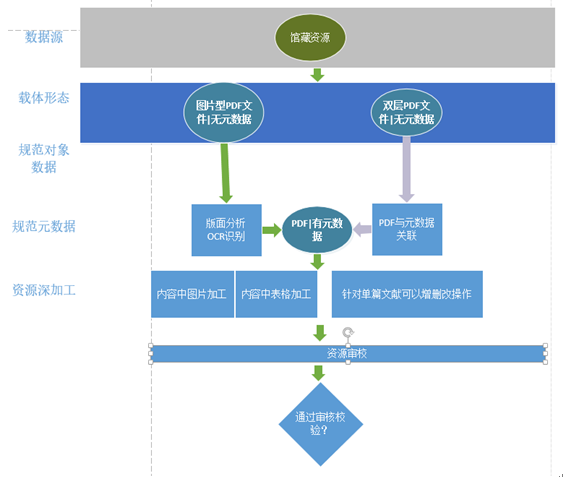
图资源加工模块
加工大体流程是:
1、 根据资源目录选择PDF文件建立 PDF版面模板,并管理
1、2、根据资源目录筛选未加工的PDF文件,关联一对应批次的版面模板,OCR自动提取标题、摘要、作者等、可人工二次编辑。
1、3、审核人员针对已加工的文献进行审核不通过驳回重新加工,通过发布。
文件状态有:知识的加工状态(未加工、加工中、待审核、审核通过状态)
Ø 数据源
数据源 主要为 外文pdf文件(图片型PDF和 双层PDF文件)。
Ø 载体形态
从资源的载体形式划分为如下五种情况:tif文件类(来源文献抢救)、pdf文件类型、带元数据的pdf、无原文的文摘数据、网页数据。
Ø 资源元数据加工
对元数据进行数据提取和数据规范。对单层的pdf进行基本元数据加工,包括数据标题、摘要、作者、关键词、时间等信息的提取。
版面分析:对同类资源的pdf文件,进行版面格式化分析,人工标注标题、摘要、作者等版面区域,对区域内的文字内容进行识别,录入到相应的元数据字段中。
扫描纸质文献:利用扫描仪对期刊等纸质文献进行扫描,扫描仪支持OCR识别,形成双层PDF文件。
PDF与元数据的关联:通过扫描仪加工的文献,进行版面分析后,把加工的对象数据与元数据进行管理。
OCR识别:对图片中的文字内容进行识别。
Ø 资源深加工
包括图表加工和引文加工。
Ø 资源组织
对各类不同来源的资源进行重新组织和知识关联
1.1.1.2 功能设计
1.1.1.2.1 版面分析
根据数字化加工要求,资源采用流水线式的数字化加工流程,将纸质资源、资料转为图像信息的电子资源。主要包括资源提档、资源整理、数据录入、批量扫描、图像编辑、资源校核、资源归还等多道工序,构成一个完整的流水线加工流程,并支持工序回馈,形成一个闭环的质量监控系统。1.1.1.2.1.1 模板定制
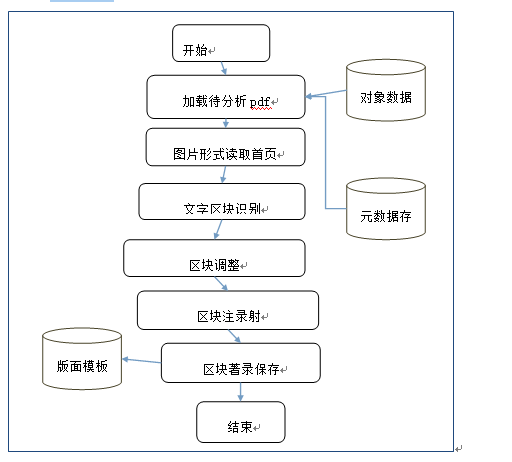
图模块定制流程图
加载待分析pdf:从文献库中提取待加工的数据一条。
图片形式读取首页:以图片形式,读取pdf首页,首页一般情况包含了标题、摘要、作者信息。
文字区块识别:通过OCR技术,对图片的文字区域进行区块识别。

区块调整:自定识别的区间,不具备一般性,需要人工进行调节,圈定区域。
区块注录映射:对识别的区域进行元数据项映射,如:把图中的第二块区域映射到标题,第五块区域映射到英文标题。
区块注录保存:把映射的区域块坐标和映射的元数据项信息保存到版面模板库中。
1.1.1.2.1.2 模板管理
对模板进行管理,包括模板预览、模板详情、模板编辑功能。Ø 区块信息数据项
| 区块信息 | 描述 |
| 区块ID | 区域块唯一标识 |
| 顶坐标 | |
| 底坐标 | |
| 左坐标 | |
| 右坐标 |
Ø 区块信息-元数据数据项映射
| 映射 | 描述 |
| 区块ID | 区域块唯一标识 |
| 元数据名称 |
元数据项规范名称,本系统映射的元数据项包括: 标题 摘要 作者 发表时间 正文区域 |
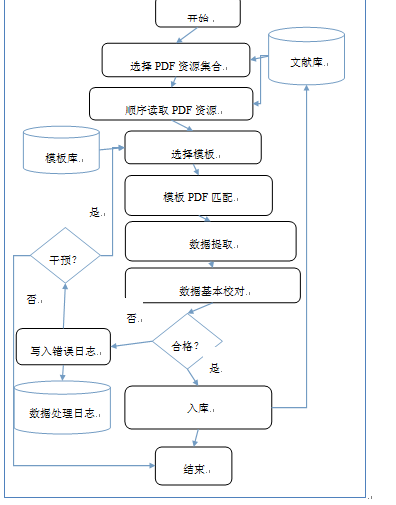
1.1.1.2.1.3 模板匹配
图模块匹配流程图
1.1.1.2.1.4 摘要提取
基于OCR内容识别后,对摘要信息的识别,摘要具有在正文独立成章节的特点,如:Abstract:XXXX的特征。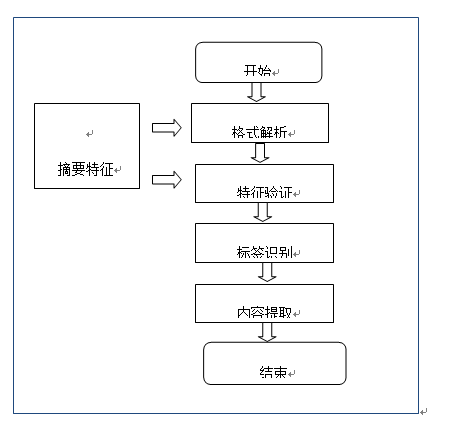
图摘要提取流程图
1.1.1.2.2 图表加工
图表加工包括对PDF文献内容中的图像和表格提取出来 ,针对每一个添加标题、标签词数据项。1.1.1.2.2.1 图表元数据提取
利用图标的标签,进行图标提取。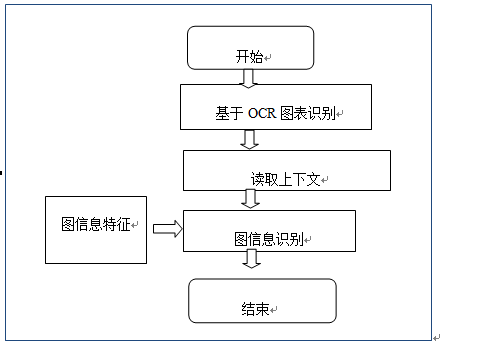
图图表元数据提取流程图
1.1.1.2.2.2 图表管理
对文档中的抽取的图标进行管理。术语信息如下:| 项目名称 | 说明 |
| 图表名称 | 从文档中抽取的图表名称 |
| 图片标签 | 加工人员提取或用户建议 |
| 图片信息 |
规格信息 图表大小 格式:jpg 图表类型 |
| 来源文献 | 所属文献 |
图片建议标签管理
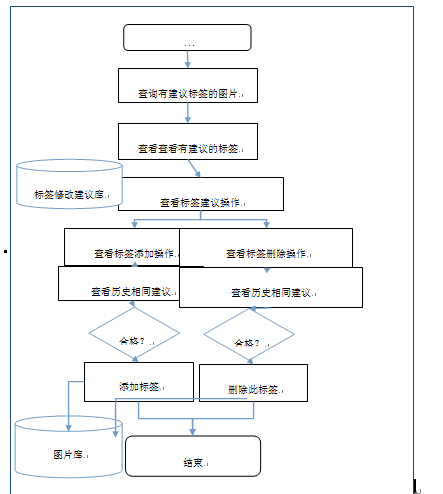
图图表管理流程图
1.1.1.2.3 数据校验
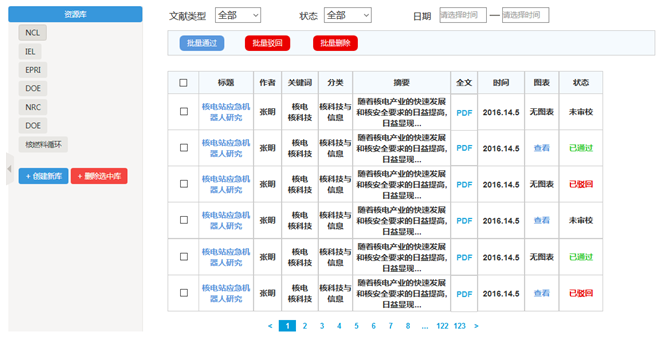
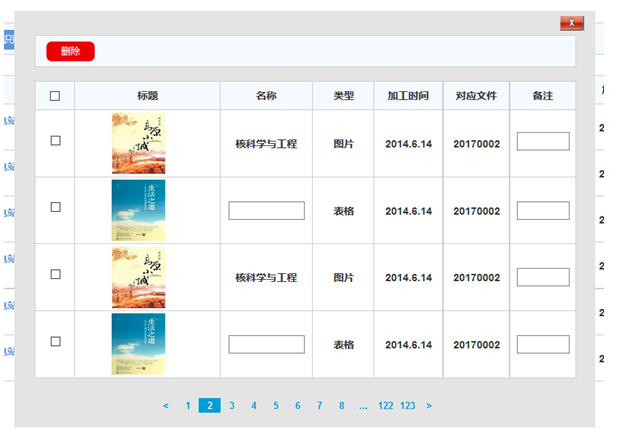
加工人员可以通过加工反馈,查看审核人员对自己加工知识的意见。为了更好的跟踪一条知识的状态,查看此知识在整个加工流程中所处的位置,可点击知识加工状态,可以查看知识的加工状态(未加工、加工中、待审核、审核通过状态)。1.1.1.3 大体模块原型如下截图所示:
 |
PDF及图片资源内容识别与智能归档系统解决方案 |
- 上一篇: 旅游景点及园艺展会游客大数据分析与应用支撑平台解决方案
- 下一篇: 工会帮扶工作管理系统解决方案